Let Event Streams Auto-Build Your Dataflow Pipeline

Brokers don’t run applications - they are a buffer between the real world and an application that analyzes events. An event stream processor (in Apache Kafka/Pulsar terms) or dataflow pipeline is an application that, given the event schema, analyzes the stream continuously to derive insights.
Such applications are necessarily stateful: They continuously modify a system model and deliver insights that result from analyzing the effects of state changes on the part of data sources in context of the previous state of the system. Any useful analysis requires knowledge of the past and may span many events or data sources. Building a dataflow pipeline to analyze events is what building a stream processing application is all about.
Different toolsets have a huge effect on the ease of application development and the quality of insights that a stream processor can deliver. The actor model (Swim, Akka) has substantial advantages over a DevOps-y Micro-Service-y approach using, say, Apache Flink or even a streaming SQL - based approach for event stream analysis because:
- Swim’s actor runtime builds a stateful dataflow pipeline directly from the event stream by dynamically creating and interconnecting actors to process events.
- Relationships between data sources can be easily modeled in the actor paradigm by enabling related actors to communicate: In Akka through message passing and in Swim through dynamic links.
- Understanding the real world always involves finding the joint state changes of multiple data sources, often in time/space (eg: they may be correlated, or geospatially “near”). Actors that are dynamically related (as changes occur) can be identified and wired up by the runtime to build a system model, on the fly.
- Deep insights always rely on finding and evaluating the effects of joint changes: Traffic prediction using real-time learning over the states of all sensors at an intersection and at all neighboring intersections enhances accuracy. When a sensor changes state this affects both predictions for its own intersection and all neighboring intersections.
Applications that rely on logical, mathematical or learned (just different math) relationships between data sources need a stateful model of the system, and it’s common to find a database of some sort at the heart of every dataflow pipeline. Update latencies are dependent on the database round-trip time, which is inevitably a million times slower than the CPU and memory, but there’s an even more tricky challenge: If events drive database updates, what triggers and runs the resulting analysis? To be clear, it’s simple to update a database row for a source when the app receives an event reporting a state change, but the computation of the effects of the change on the system - the resulting dependencies - is impossible, because a database doesn’t store those. Time - and behavior over time - play a critical role in understanding any dynamic system, and databases (including time-series databases) don’t help with analysis over time.
The types of applications that can be built with and executed by any stream processing platform are limited by how well the platform manages streams, computational state, and time. We also need to consider the computational richness the platform supports - the kinds of transformations that you can do - and the contextual awareness during analysis, which dramatically affects performance for some kinds of computation.
There are two approaches to stateful analysis that I will point to, before spending more time on a powerful “feature” of the actor model that lets us build dataflow pipelines on the fly, directly from streaming data.
Apache Flink Apache Flink is a distributed processing engine for stateful computation on unbounded and bounded data streams. With regards to streaming data, both Swim and Flink support analysis of:
- Bounded and unbounded streams: Streams can be fixed-sized or endless.
- Real-time and recorded streams: There are two ways to process data – “on-the-fly” or “store then analyze”. Both platforms can deal with both scenarios. Swim can replay stored streams, but we recognize that doing so affects meaning (what does the event time mean for a recorded stream?), and accessing storage (to acquire the stream to replay) is always desperately slow.
Swim does not store data before analysis – computation happens as soon as data is received. Swim also has no view on the storage of raw data after analysis: By default Swim discards raw data once it has been analyzed and transformed into an in-memory stateful representation. But you can keep it if you need to - after analysis, learning, and prediction. Swim supports a stream per source of data - this might be a topic in the broker world - and billions of streams are quite manageable. Swim does not need a broker but can happily consume events from a broker, whereas Flink does not support this.
Every useful streaming application is stateful. (Only applications that apply simple transformations to events do not require state - the “streaming transfer and load” category for example.) Every application that runs business logic needs to remember intermediate results to access them in later computations. The key difference between Swim and Flink relates to what state is available to any computation.
Here’s where Swim stands head and shoulders above every other approach: In Flink the context in which each event and previous state retained between events is interpreted is related to the event (and its type) only. An event is interpreted using a stateful function (and the output is a transformation of the sequence of events). A good example would be a counter or even computing an average value over a series of events. Each new event triggers computation that relies only on the results of computation on previous events.
The Actor Model SwimOS (Apache 2.0 OSS) - is a stream processor that delivers continuous intelligence from streaming event data. An example app that continuously tracks satellites, using Kafka and public data, is here.
SwimOS
- Makes it easy to develop applications that statefully process streaming data on the fly to deliver high-resolution insights for visualization, applications, and persistence, analyzing, learning and predicting on the fly using an “analyze, act, and then store” architecture,
- Auto-scales application infrastructure based on event rates and computational complexity to meet real-time processing needs,
- Is a 2MB set of extensions to Java (we use GraalVM for a runtime),
- Is fast! So we can do real-time analysis, learning, and prediction using in-memory stateful processing.
SwimOS uses an “analyze, act, and then store” architecture: This allows continuous analysis and prediction in memory, without an additional data store. Insights are continually available – enabling a real-time response.
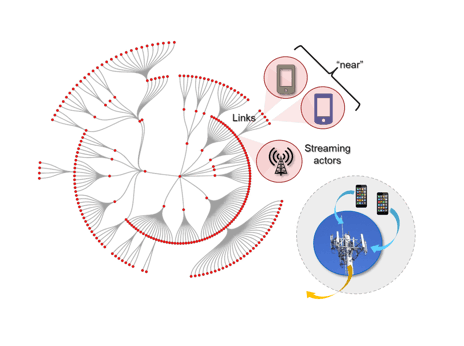
Developers create simple object-oriented applications in Java - and then SwimOS uses streaming data to build a graph of stateful, concurrent actors - called Web Agents - that are “digital twins” of data sources. Usually, each corresponds to a Kafka topic. Each actor processes event data from a single source and keeps its state in memory. They link to each other based on context discovered in the data, dynamically building a graph that reflects contextual relationships between sources like proximity, containment, or even correlation.
The resulting graph is a bit like a “LinkedIn for things”: actors that are digital twins of real-world assets dynamically interlink to form a graph, based on real-world relationships discovered in the data. These relationships may be specified by the developer (eg: an intersection contains lights, loops, and pedestrian buttons). But data builds the graph: as data sources report their status, they are linked into the graph. Linked agents see each other’s state changes in real-time. Web agents continuously analyze, learn and predict from their own states and the states of agents they are linked to, and stream granular insights to UIs, brokers, and enterprise applications.
SwimOS benefits from in-memory, stateful, concurrent computation. Streaming implementations of key analytical, learning, and prediction algorithms are included in SwimOS, but it is also easy to interface to applications on Spark, where it replaces Spark Streaming mini-batches with an in-memory, stateful graph of Web Agents that can directly deliver RDDs to Spark, simplifying applications considerably.
We used SwimOS to build an app for a mobile operator to continuously aggregate and analyze 5PB of streaming data per day from thousands of cell towers that connect millions of subscribers. The application enables the provider to continuously optimize and predict connection quality and ensure a superior network experience for their subscribers. The app is only a few thousand lines of Java, but the runtime graph built by SwimOS spans 40 instances.