Implementing Natural Language Query for Streaming Data Applications
Introduction
For developers building real-time data applications -— whether it’s transit systems or IoT networks —- enabling natural language query (NLQ) can significantly enhance user interaction. However, integrating NLQ with structured, real-time data presents unique challenges. For instance, how do you enable an NLQ system to dynamically identify the right data source or Web Agent based on the user’s query?
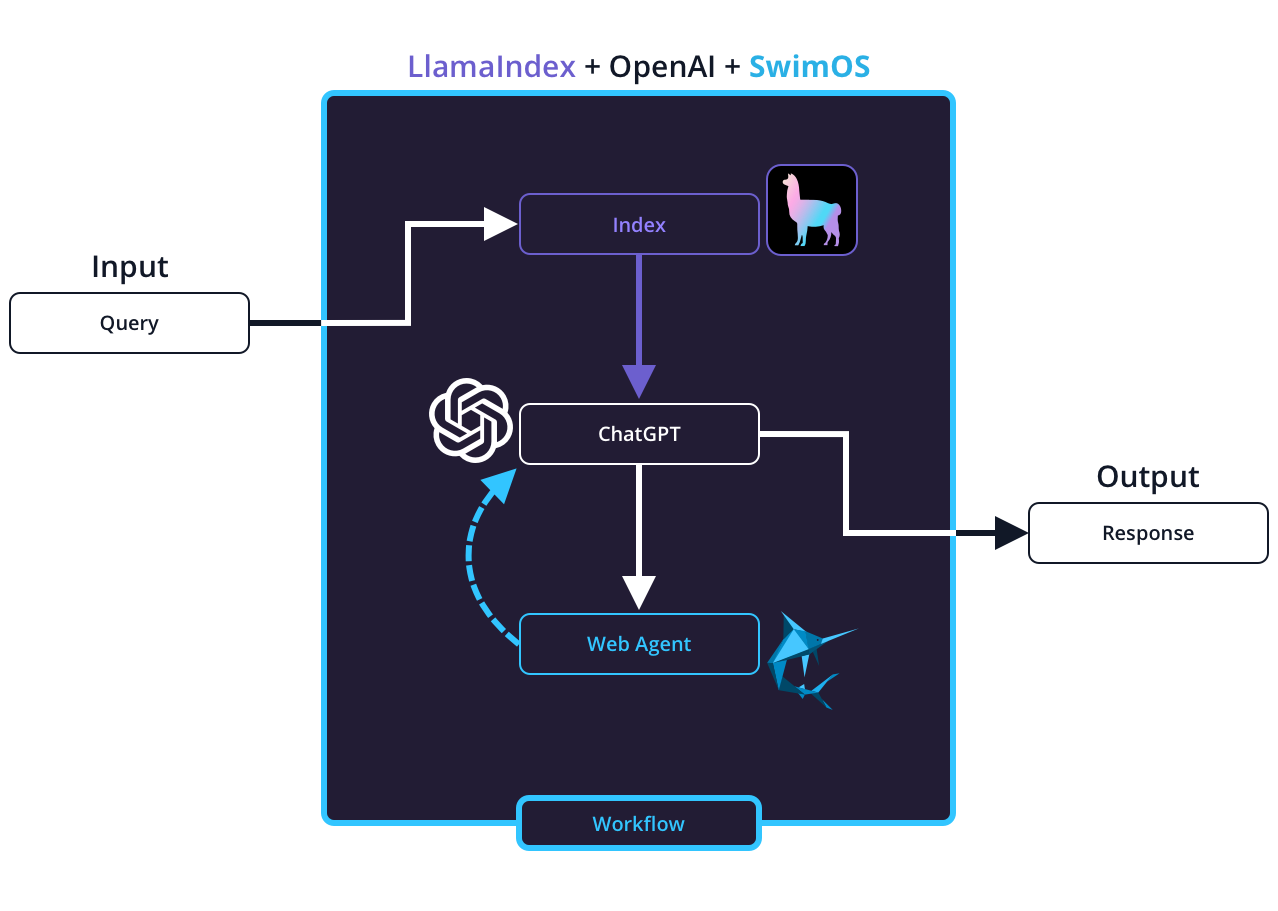
In this post, we explore how to implement an NLQ system for streaming data applications using LlamaIndex for context storage and ChatGPT for language understanding. We’ll walk through a practical example of using SwimOS Web Agents to retrieve dynamic transit data, demonstrating how NLQ can be layered on top of a streaming data system to provide real-time, contextual answers.
We focus specifically on how to dynamically identify the correct Web Agent (e.g., transit agency, vehicle, or state) using LlamaIndex as a static context store. This ensures that the system first retrieves the right agent before querying real-time data streams for an accurate and detailed response.
Transit Application
We will work with a live transit system that has been implemented with SwimOS Web Agents to represent the key entities of interest:
In this transit system, data is structured hierarchically:
- Country –> States (e.g., USA)
- State –> Agencies (e.g., Unitrans in California)
- Agency –> Routes (e.g., Route A, Route B)
- Vehicles –> Routes (e.g., Bus LMU_4000)
This means a user query might look like, “What is the average speed of vehicles in California?” or “How many active agencies are there in New York?”. To answer these queries accurately, our system needs to understand this hierarchy and retrieve relevant details.
We can programmatically explore this data using the SwimOS command line tool:
- Install:
npm install -g @swim/cli - The output will be similar to JSON but in an extended version called Recon.
To retrieve a list of agencies within the country, use the following command:
swim-cli get -h warp://transit.services.nstream-demo.io -n /country/US -l agencies
The output is in Recon, an extended version of JSON used by SwimOS. Learn more about recon:
@update(key:"/agency/US/FL/jtafla")@agency{id:jtafla,state:FL,country:US,index:16}
@update(key:"/agency/US/FL/nova-se")@agency{id:nova-se,state:FL,country:US,index:25}
@update(key:"/agency/US/FL/sria")@agency{id:sria,state:FL,country:US,index:28}
...
For vehicles:
swim-cli get -h warp://transit.services.nstream-demo.io -n /agency/US/N-CA/unitrans -l vehicles
Example Output:
@update(key:"/vehicle/US/MD/jhu-apl/1")@vehicle{id:"1",uri:"/vehicle/US/MD/jhu-apl/1",agency:jhu-apl,routeTag:internal,dirId:inbound,latitude:39.16916,longitude:-76.894165,speed:19,secsSinceReport:3,index:0,heading:NW,routeTitle:"Blue Line"}
@update(key:"/vehicle/US/MD/jhu-apl/10")@vehicle{id:"10",uri:"/vehicle/US/MD/jhu-apl/10",agency:jhu-apl,routeTag:fullservice,dirId:inbound,latitude:39.165382,longitude:-76.89058,speed:19,secsSinceReport:4,index:0,heading:S,routeTitle:"Purple Line"}
...
What is Retrieval Augmented Generation (RAG)?
RAG combines the retrieval of relevant data with the generative capabilities of models like ChatGPT. Here’s how it works:
- When a user asks a question, the system first searches through a context store (typically a vector store like LlamaIndex) to find related information.
- It then feeds this context into the language model (ChatGPT), so the model can provide a more accurate and context-aware answer.
In this system, we store structured transit data (e.g., states, agencies) in LlamaIndex, and use it to improve how ChatGPT handles queries. Without this context, ChatGPT will have no way to provide responses for highly specific structured data like transit. For instance, when a user asks, ‘What are the agencies in California?’, the system first retrieves the list of agencies from the context store using LlamaIndex. This context is then fed into ChatGPT, enabling it to generate an accurate and specific answer.
Data Structure Explanation
We are starting with static data, which we can load or set up during initialization since the information does not change frequently. In this case, we are modeling a transit system with multiple entities:
- States: This represents the geographic region (e.g., California, “CA”).
- Agencies: These are the organizations or transport operators (e.g., Unitrans).
- Routes: These represent the transit routes for each agency (e.g., Route A, Route B).
- Vehicles: These are individual transit vehicles, such as buses, that belong to routes (e.g., LMU_4000, LMU_4001).
The goal is to store this information in LlamaIndex so that ChatGPT can retrieve relevant details based on a user’s query.
Static Data Structure Breakdown
The static data we’re using is structured as a dictionary containing a list of states, where each state contains information about its agencies. Agencies, in turn, contain information about their routes and vehicles. We will be creating a static dataset that will be used as context for ChatGPT. Here’s a breakdown of the data we’ll be working with:
- State Information:
- Each state is defined with attributes like
name,code, andbounding_box(latitude and longitude range).
- Each state is defined with attributes like
- Agency Information:
- Agencies are nested inside each state. They have attributes such as
id,name, andbounding_box.
- Agencies are nested inside each state. They have attributes such as
- Routes and Vehicles:
- Each agency contains a list of routes and vehicles. The vehicles are mapped to a specific route.
static_data = {
"states": [
{
"name": "Northern California",
"code": "N-CA",
"bounding_box": {
"min_latitude": 36.7783, # Lower boundary of Northern California
"max_latitude": 42.0095, # Northern boundary of the state
"min_longitude": -124.4096, # Western boundary of the state
"max_longitude": -119.4179 # Eastern boundary of Northern California
},
"agencies": [
{
"id": "unitrans",
"name": "Unitrans",
"bounding_box": {
"min_latitude": 38.533043,
"max_latitude": 38.560875,
"min_longitude": -121.78493,
"max_longitude": -121.71184
},
"routes": [
{"tag": "A", "name": "Route A"},
{"tag": "B", "name": "Route B"},
],
"vehicles": [
{"id": "LMU_4000", "route": "A"},
{"id": "LMU_4001", "route": "B"},
]
}
]
}
]
}
In this example, the Northern part of the state of California is home to an agency named Unitrans. This agency operates two routes (Route A and Route B) and manages two vehicles (LMU_4000, LMU_4001), each assigned to a route.
Converting Static Data into Documents for LlamaIndex
We now need to take this nested static data and convert it into documents that can be indexed in LlamaIndex. This process involves:
- State-Level Document: Each state is converted into a document that stores its metadata, such as its name, bounding box, and list of agencies.
- Agency-Level Document: Each agency within a state is stored as a document, capturing its name, bounding box, routes, and vehicles.
This structure will later allow us to search the index for states, agencies, routes, or vehicles in response to user queries.
# Function to create a document for each static data entry, with relationships
def create_documents_with_relationships(data):
documents = []
for state in data["states"]:
# Create a document for each state
state_json = json.dumps({
"State": state["name"],
"Code": state["code"],
"BoundingBox": state["bounding_box"],
"Agencies": [agency["id"] for agency in state["agencies"]]
}, indent=4)
state_doc = Document(text=state_json, metadata={"type": "state", "code": state["code"]})
documents.append(state_doc)
for agency in state["agencies"]:
# Create a document for each agency within the state
agency_json = json.dumps({
"Agency": agency["name"],
"ID": agency["id"],
"BoundingBox": agency["bounding_box"],
"State": state["name"],
"Routes": [route["tag"] for route in agency["routes"]],
"Vehicles": [vehicle["id"] for vehicle in agency["vehicles"]]
}, indent=4)
agency_doc = Document(text=agency_json, metadata={"type": "agency", "id": agency["id"], "state": state["name"]})
documents.append(agency_doc)
return documents
Step 2: Querying Context from LlamaIndex
With the static context stored, we can now retrieve relevant data when a user query comes in. For example, if the user asks “What are the agencies in California?”, we can pull the agency information from the vector store using LlamaIndex.
# Initialize a vector store
documents = create_documents_with_relationships(static_data)
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
# Query function to demonstrate usage
def query_static_data(query):
results = query_engine.query(query)
return results
# Example query: "What are the agencies in Northern California?"
query_result = query_static_data("What are the agencies in Northern California?")
print(query_result)
Step 3: Dynamically Choosing the Correct Web Agent Using Query Context
Now that we have stored the hierarchical data using LlamaIndex, the next challenge is to dynamically determine the appropriate Web Agent based on a user’s natural language query.
For California, which is split into two regions (N-CA and S-CA), the user query can focus specifically on either region.
When combined with ChatGPT, we can use the retrieved context to guide the identification of the correct Web Agent (e.g., country, state, agency, or vehicle) and which lane to query based on the user’s question.
Here’s how we handle this:
- Retrieve Relevant Context: Before ChatGPT processes the query, we use LlamaIndex to retrieve context such as the states, agencies, and routes.
- Pass the Retrieved Context into ChatGPT: The retrieved context is then passed into ChatGPT to help it generate an accurate response.
- Construct the Correct API Request: Using the context provided, ChatGPT constructs the correct
nodeUriandlaneUrito issue the API call.
Here’s the updated Python code to reflect this behavior:
from openai import OpenAI
from llama_index.core import Document, VectorStoreIndex
# Query with OpenAI's updated API using the combined context
def query_with_openai(user_query, context):
prompt = f"""
You are an AI agent managing a streaming API for transit data. Based on the following user query and context, you need to
determine the correct Web Agent (country, state, agency, or vehicle) and the appropriate lane to query.
All states are represented by their two-letter state code except California, which is split into N-CA and S-CA.
Context: {context}
User Query: {user_query}
The Web Agents are:
- Country: /country/:id (e.g., /country/US)
- State: /state/:country/:state (e.g., /state/US/N-CA and /state/US/S-CA for California)
- Agency: /agency/:country/:state/:id (e.g., /agency/US/N-CA/unitrans)
- Vehicle: /vehicle/:country/:state/:agency/:id (e.g., /vehicle/US/S-CA/west-hollywood/116)
Your job is to output a JSON object with the nodeUri and laneUri for the correct agent and lane based on the user query.
Example response: nodeUri
"""
# Call OpenAI API for response -- llm_client = OpenAI()
response = llm_client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are an AI assistant for managing a streaming API."},
{"role": "user", "content": prompt},
],
max_tokens=1000
)
return response.choices[0].message['content'].strip() # Fixed API response access
# Example usage of OpenAI function
response = query_with_openai(user_query, query_static_data("What are the agencies in Northern California?"))
print(response)
Conclusion
In this post, we demonstrated how to build a context-driven natural language query system using LlamaIndex and ChatGPT. By retrieving hierarchical data dynamically and passing it as context to the language model, we significantly enhance its ability to answer structured queries accurately. This process allows us to handle complex, real-world datasets—like transit systems—by bridging the gap between natural language understanding and structured data retrieval.
You can find the corresponding source in the file implementing_nlq.py located in the repo below under scripts.
Keep an eye out for the next installment where we’ll subscribe to Web Agents and incorporate their real-time context.